
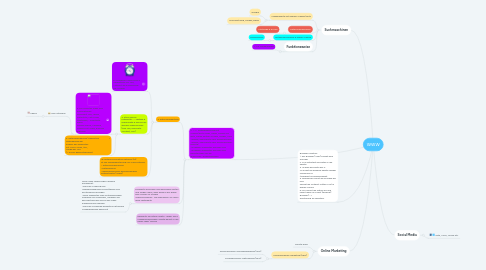
1. 2 . + 7. Datengewinnung mit Crawler/Bots Video, News, Google Ad Bots, Media Partner Google, Images, APIs >Spider, Searchbots oder Suchmaschine >Spider, Searchbots oder Suchmaschine- Roboter >Aufgabe: Webseiten aufrufen und >Aufgabe: Webseiten aufrufen und herunterladen für die Quellcode--AnalyseAnalyse
1.1. 3. Datenverarbeitung
1.1.1. 6. Scheduler>Sammlung & Verwaltung von URL, >steuert die aussendung der Crowler
1.1.2. 4. Store Server Filterkette --> gültige & erwünschte R essourcen werden angenommen (Dok Typ, Duplicate Content, URL)
1.1.2.1. 5. Documenten Index Dok Informationen: Dokument Typ, Länge, Seitentitle, Meta Tags, Hostname,… Invertierte Index Google Dance, Caffeine, Mobile First Index, Ranking Faktoren
1.1.2.1.1. User-Interface
1.1.2.2. 5. Datenspeicherung/ Repository > Speicherung der Kopien der Webseiten mit HTML Code, ÜRL, Länge der URL (> DocID gekenntzeichnet
1.1.3. IR SystemInformation Retrieval (IR) ist die Wiederherstellung von Informationen. • Datennormalisierung •Datenanalyse •Generierung einer durchsuchbaren Datenstruktur (Index)
1.2. Freshbots besuchen neu gefundene Seiten und sorgen dafür, dass diese in der Regel sehr schnell im Google Index erscheinen . Sie analysieren vor allem reine Textinhalte
1.2.1. neue Index Technologie Caffeine ermöglicht: •dass der Crawling und Indexierungsprozess schrittweise und kontinuierlich erfolgen •neue Webseiten oder Aktualisierungen innerhalb von Sekunden, nachdem sie gecrawlt worden sind in den Index aufgenommen werden. •dass der Suchende wesentlich aktuellere Suchergebnisse bekommt
1.3. Deepbots für ältere Inhalte... Bilder PDFs Indexerscheinungen Inhalte dauert in der Regel Tage/ Woche
2. Online Marketing
2.1. Smarte Ziele
2.2. Suchmaschinen-Marketing (SEM)
2.2.1. Suchmaschinen-Anzeigenwerbung (SEA)
2.2.2. Suchmaschinen-Optimierung (SEO)
3. Suchmaschinen
3.1. Indexbasierte mit eignem Crawler/Bots
3.1.1. Google
3.1.2. Microsoft Bing, Yandex, Baidu
3.2. Metasuchmaschinen
3.2.1. Startpage & Ecosia
3.3. Metasuchmaschine & eigner Crawler
3.3.1. DuckDuckGo
3.4. Funktionsweise
3.4.1. 1. + 8. Suchanfragen